
Implementing AI Feedback Loops: A Practical Guide for Business Systems
Why feedback loops matter
AI features degrade without signals. A feedback loop captures how your model performs in the real world, letting you turn live behavior into measurable improvements. Done well, it reduces surprises, focuses engineering effort, and raises business value.
- Prevents silent performance drift
- Prioritizes improvements that impact users
- Makes model updates repeatable and auditable
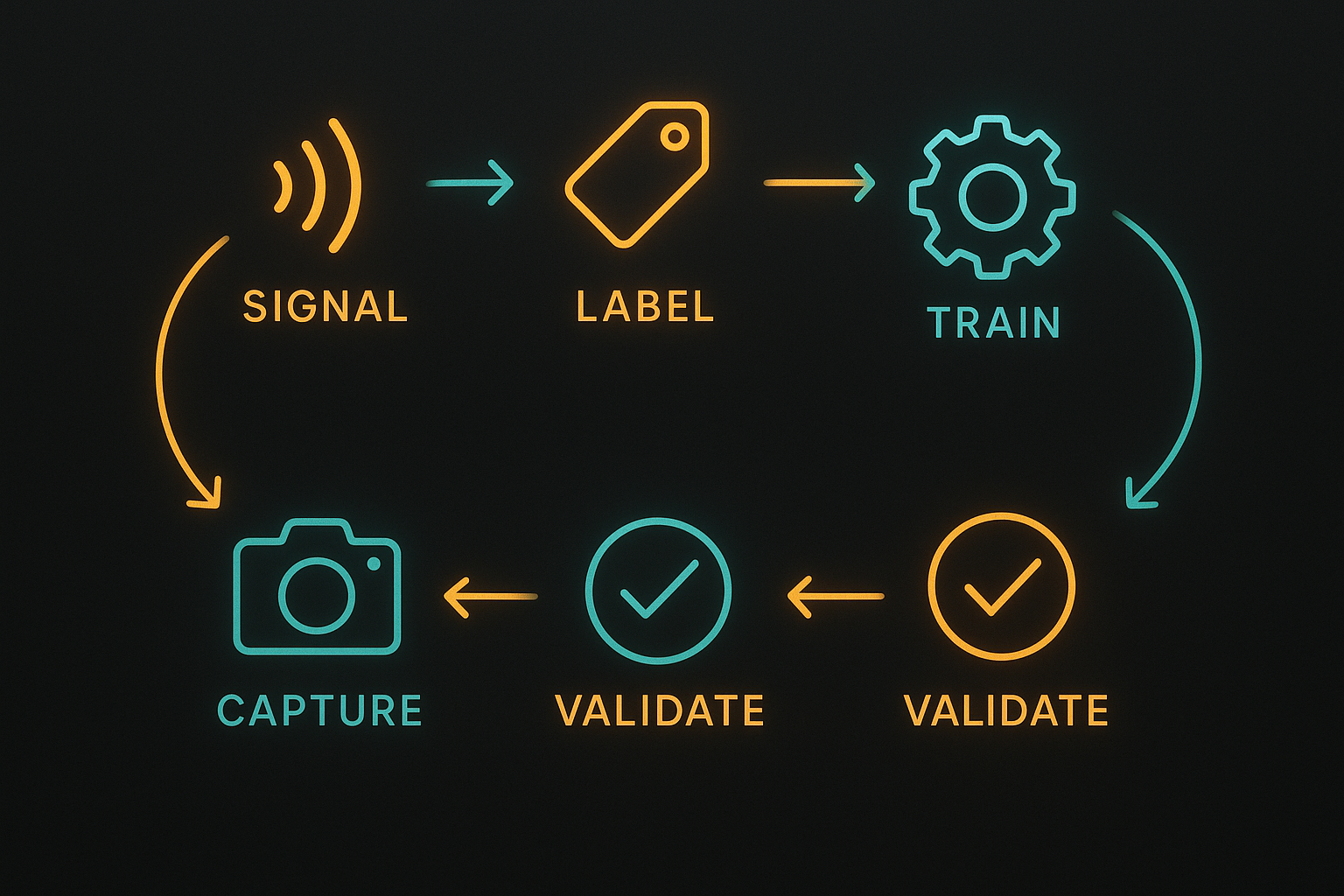
What a feedback loop actually is (brief)
A feedback loop is the repeated process of:
- Capturing signals from production (user actions, errors, business KPIs)
- Turning those signals into labeled examples or metrics
- Training and validating a candidate model
- Deploying and monitoring the model
Each iteration should be measurable and small enough to troubleshoot.
Step 1 — Instrument the right signals
Start with a short list of production signals that directly map to user value or risk:
- Explicit user feedback (thumbs up/down, corrections)
- Behavioral signals (clicks, conversions, time-to-complete)
- System signals (prediction confidence, latency, error rates)
- Business KPIs (retention, revenue per user)
Practical tip: add context to signals (inputs, model version, timestamp) so you can reproduce the conditions that generated them.
Step 2 — Define quality and impact metrics
Separate model-centric metrics from business metrics:
- Model metrics: calibration, precision/recall, false positive rate, latency
- Business metrics: task completion rate, cost per conversion, churn change
Choose 2–3 primary metrics to drive decisions. Use secondary metrics to diagnose regressions.
Step 3 — Sample and label efficiently
You don’t need to label everything. Use a sampling strategy:
- Random sampling for baseline quality
- Error-focused sampling for edge cases (low confidence or high-cost errors)
- Time-based sampling to detect drift
For labeling, create lightweight interfaces and clear guidelines. Track labeler agreement and sample complexity so you know when labels are unreliable.
Step 4 — Build a repeatable training pipeline
Automate the pipeline but keep it transparent:
- Version inputs, labels, and model code
- Make training runs reproducible with manifests and seed values
- Capture evaluation artifacts (confusion matrices, calibration plots)
Keep retraining cadence aligned to signal volume. High-volume features can be retrained weekly; low-volume ones might be monthly or on-demand.
Step 5 — Validate and roll out safely
Use staged rollouts and guardrails:
- Shadow deployments to compare predictions without affecting users
- Canary releases to small cohorts with monitoring
- Automated rollback triggers for metric regressions
Document acceptance criteria for promotion from staging to production.
Step 6 — Monitor, alert, and act
Monitoring should cover both stability and value:
- Stability: latency, error spikes, infrastructure costs
- Performance: metric trends, distribution drift, confidence shifts
Set alert thresholds that indicate real problems (not noise). When alerts fire, record the diagnosis and remediation as part of the feedback loop so the learning is captured.
Step 7 — Governance, privacy, and compliance
Make data handling explicit:
- Record data sources and retention policies
- Ensure labeling and storage comply with privacy rules
- Keep audit logs for training data and model versions
Low-friction documentation reduces risk and speeds audits.
Practical checklist (one page)
- Instrument signals with context and model metadata
- Define 1–2 primary metrics tied to business outcomes
- Implement strategic sampling for labeling
- Automate reproducible training runs with versioning
- Use shadow/canary deployments and rollback policies
- Monitor stability and performance; set meaningful alerts
- Document data governance and retention rules
Small example you can implement this week
- Pick one AI feature (autocomplete, recommendation, classification).
- Add a simple "thumbs up/down" capture with model version and input snapshot.
- Weekly: export low-confidence and random samples, label 100–200 examples.
- Run one automated training job, evaluate, and do a canary rollout if metrics improve.
This yields a working loop without major engineering upfront.
Tools and approach
- Data capture: lightweight event pipelines (Kafka, Segment, or server logs)
- Labeling: small internal apps or annotation platforms (Label Studio, Prodigy)
- Training pipelines: CI/CD for ML (Airflow, GitHub Actions, CI for model scripts)
- Monitoring: Prometheus/Grafana or hosted ML monitoring (Seldon, Fiddler)
Pick tools you can integrate quickly; avoid big rewrites early on.
Closing: run small, measure fast
A feedback loop doesn’t need to be perfect. Start small, instrument what matters, and make each iteration reproducible. Over time, these habits reduce risk and focus work on the improvements that matter most to the business.
Practical takeaway: implement one small loop this week—capture a signal, label 100 examples, run a training job, and canary the result.