
What Good AI Adoption Looks Like After the Pilot
Moving past pilots means your AI tools are no longer curiosities — they're components of day-to-day work. That change is visible in a few concrete, repeatable signals. This post lists those signals, explains why they matter, and gives practical steps to make a pilot stick.
What "after the pilot" actually means
A pilot proves feasibility. After the pilot you want durability: predictable outcomes, manageable risk, and clear ownership. Durability is not perfection. It's the combination of reliable performance, observability, governance, and human workflows that let a system run in production without constant firefighting.
Key signals that an AI workflow is becoming durable
These are practical signs you can check in your team and systems.
1. Stable, repeatable outcomes
- The model or automation produces consistent outputs for the same inputs.
- You can reproduce issues and test fixes in a staging environment.
- Your team trusts the outputs enough to act on them without double-checking every time.
Why it matters: Repeatability lets you measure improvements and make incremental changes safely.
2. Measurable, prioritized metrics
- You track a small set of business-aligned KPIs (accuracy, time saved, error catch rate, conversion lift).
- Metrics are tied to decisions: if the metric moves, you know who should respond and how.
Why it matters: Metrics turn vague benefits into operational levers.
3. Observability and alerts
- Dashboards show throughput, error rates, latency, feedback volume, and model confidence distributions.
- You have alerts for threshold breaches (spikes in errors, sudden drop in confidence, data schema changes).
Why it matters: Observability moves you from reactive to proactive maintenance.
4. Clear human–automation handoffs
- The workflow defines exactly when the system acts, when a human reviews, and how to escalate.
- Handoffs have simple, documented checks (e.g., confidence < 0.6 triggers human review).
Why it matters: Well-defined handoffs reduce inconsistent decisions and liability.
5. Ownership and governance
- A named owner (product, ops, or domain team) is accountable for outcomes.
- Policies exist for data use, model updates, and rollback procedures.
Why it matters: Ownership prevents orphaned automations and clarifies who updates what.
6. Predictable costs and performance
- You understand the compute, API, and maintenance costs and how they scale.
- Latency and throughput meet user needs; degradations have fallback paths.
Why it matters: Predictability keeps the solution viable as usage grows.
7. Clear data lineage and versioning
- Inputs and outputs are logged with timestamps and version tags for models, prompts, or code.
- You can trace a specific decision back through data and model versions.
Why it matters: Lineage supports debugging, compliance, and responsible change.
8. Feedback loop and retraining plan
- You collect labeled examples or corrections from users.
- There's a cadence for retraining or prompt updates and a safe process to test them.
Why it matters: Systems drift; planned updates keep performance from degrading.
9. User adoption and confidence
- Day-to-day users routinely use the AI part of the workflow and report it saves time.
- Support requests are predictable and handled by defined channels.
Why it matters: Adoption validates that the tool solves real problems.
10. Compliance and security checks
- Data handling meets legal and internal security requirements.
- Access controls and secrets management are in place.
Why it matters: Risk management becomes essential as automation touches more data and decisions.
What to do when signals are missing
If you piloted successfully but don't see these signals, prioritize fixes in this order:
- Ownership: assign a responsible team or person now.
- Observability: add basic logging and a small dashboard for the most important metrics.
- Human handoffs: document the decision points where humans must inspect or override.
- Cost and performance: add simple load and cost tracking to understand scale limits.
These four moves unlock the rest: once someone owns it and you can see what happens, you can set retraining cadences, add lineage, and tighten governance.
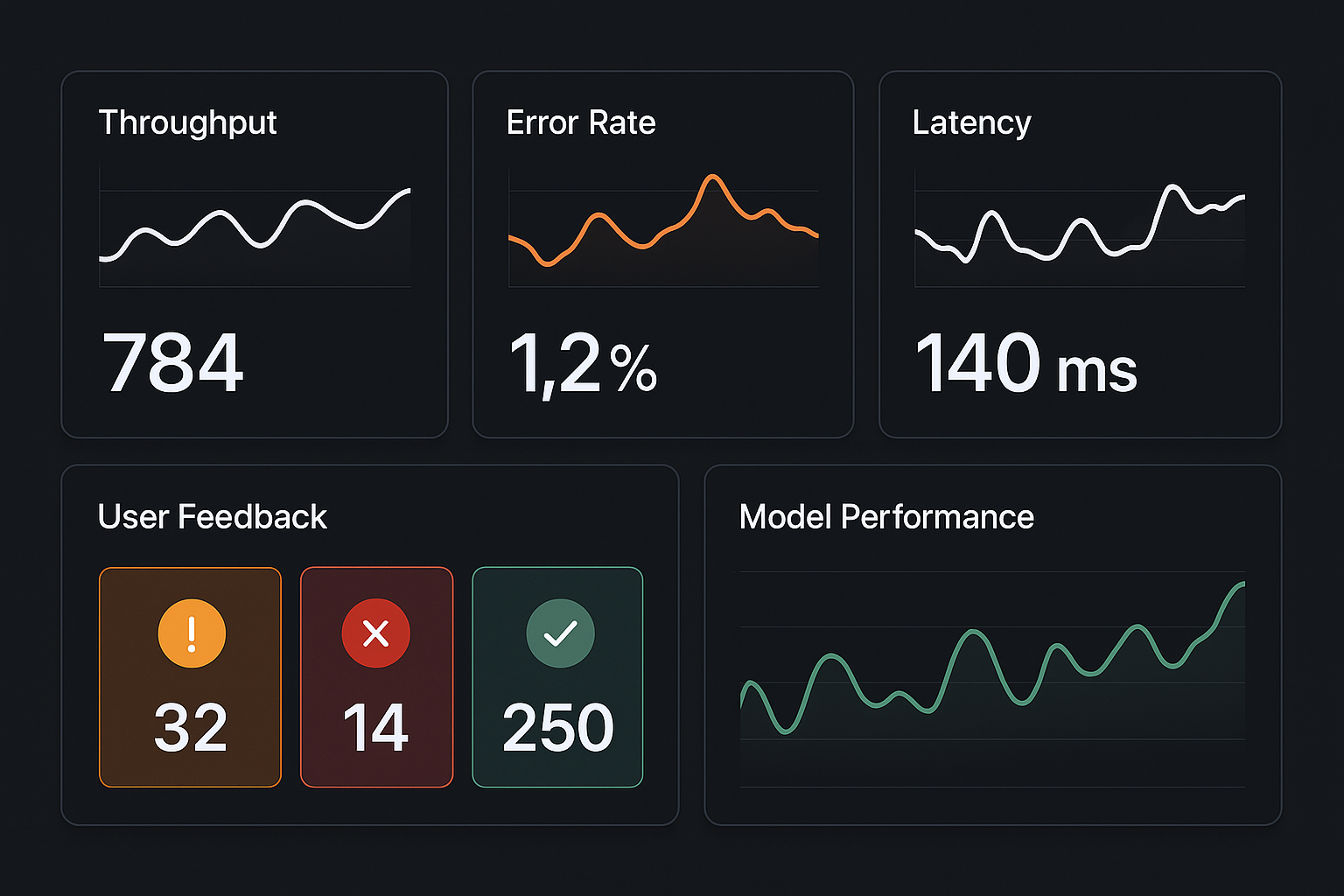
Steps to operationalize a durable AI workflow
A short, pragmatic sequence you can run through in 4–8 weeks.
- Run a day-in-the-life mapping
- Map inputs, AI steps, human reviews, outputs, and failure modes. Keep it one page.
- Pick 3 metrics to monitor
- Choose one business outcome, one quality metric, one reliability metric.
- Build minimal observability
- Log inputs/outputs, confidence, timestamps, and model/version IDs. Add a lightweight dashboard and an alert.
- Define handoff rules
- When does the AI act automatically? When is a human required? Write a one-paragraph runbook.
- Assign ownership and SLAs
- Owner, who responds to alerts, and a simple SLA for incident resolution.
- Add feedback collection
- Capture corrections and route them to the owner for triage; store them for retraining.
- Establish a retraining/testing schedule
- Monthly or quarterly depending on drift risk. Always test in staging first.
- Review costs and security
- Set budget alerts and confirm data governance controls.
A practical checklist to run before full rollout
- Named owner and backup
- 1-page workflow map
- 3 monitored KPIs and dashboards
- Alerting thresholds and escalation path
- Human review rules documented
- Logging with model/version IDs
- Feedback capture and triage process
- Retraining/test cadence defined
- Cost and security checks completed
Common traps to avoid
- Treating an early win as "done" without observability.
- Adding too many automated decisions at once — go incremental.
- No rollback plan for a bad update.
- Hiding the AI step from users; transparency builds trust.
Final notes
Durable AI adoption is less about a single technology and more about predictable operations: repeatable outcomes, clear ownership, measurable impact, and the infrastructure to observe and respond. Focus your early post-pilot work on those pieces; you can polish UX and advanced optimizations later.
Practical takeaway: Assign an owner, add a small set of dashboards and alerts, and document the human–machine decision points. Those three steps turn many pilots into reliable, usable systems.